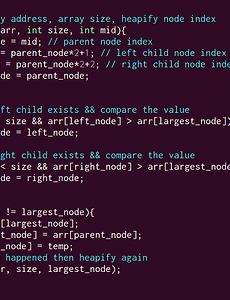
Algorithm5 [C] Countsort:: 계수정렬 안녕하세요. 우주신 입니다. 이번 포스팅에서는 계수정렬(Count Sort)에 대해 알아보겠습니다. 앞선 포스팅에서의 삽입, 퀵, 힙 정렬 등의 방법은 정렬할 때 두 값을 비교하며 정렬을 했다.이를 Comparison Sort라고도 부르는데, 이와 반대로 계수정렬은 비교를 하지 않고 정렬을 하기 때문에 Non-Comparison Sort의 방법 중 하나이다. [4 1 3 4 3] 리스트를 정렬하면서 자세히 알아보자. 우선, 두 개의 리스트 B, C를 만들어준다. B는 A 리스트를 정렬하여 결과물을 넣어줄 리스트이다.C(Counting List)의 Index는 곧 A의 요소이고, C의 값은 A의 요소들의 갯수이다.예를 들어 A에 4가 총 몇 개 나온지는 C의 4번째 Index를 보면 알 수 있다. 그러므로.. 2018. 7. 28. [C] Quicksort:: 퀵정렬 안녕하세요. 우주신 입니다. 오늘은 퀵정렬(Quick Sort)에 대해 포스팅 하겠습니다.퀵정렬은 시간복잡도가 O(nlogn)으로 실제로 매우 효율적인 알고리즘이라 자주 사용된다. 우선, 위키피디아의 퀵정렬 정의를 참고해보자. 퀵 정렬은 분할 정복(divide and conquer) 방법을 통해 리스트를 정렬한다.리스트 가운데서 하나의 원소를 고른다. 이렇게 고른 원소를 피벗(Pivot)이라고 한다.피벗 앞에는 피벗보다 값이 작은 모든 원소들이 오고, 피벗 뒤에는 피벗보다 값이 큰 모든 원소들이 오도록 피벗을 기준으로 리스트를 둘로 나눈다. 이렇게 리스트를 둘로 나누는 것을 분할이라고 한다. 분할을 마친 뒤에 피벗은 더 이상 움직이지 않는다.분할된 두 개의 작은 리스트에 대해 재귀(Recursion)적으.. 2018. 6. 24. [C] Heap Sort:: 힙정렬 안녕하세요. 우주신 입니다. 오늘은 힙 정렬(Heap Sort)에 대해 알아보겠습니다. 힙 정렬(Heap Sort)은 힙(Heap) 성질을 이용하여 정렬(Sort)하는 방식이다. 힙은 최대값 및 최솟값을 찾아내는 연산을 빠르게 하기 위해 고안된 완전이진트리(Complete binary tree)를 기본으로 하는 자료구조이다. 힙은 두 가지가 종류가 있는데, 최대 힙(Max Heaps), 최소 힙(Min Heaps)이다. 최대 힙은 부모가 자식 노드의 값보다 더 큰 노드 값들로 구성된 트리이다.밑의 그림은 최대 힙의 예시이다. [용어 정리]- 노드, 인덱스 = 주소- 노드 값 = 주소 안에 있는 값 그리고 트리는 당연히 배열로 표현할 수 있다. 이 때, 부모 인덱스가 i라면 왼쪽 자식은 2 * i, 오른쪽.. 2018. 6. 23. [Python] Merge Sort: 병합 정렬 안녕하세요. 우주신 입니다. 오늘은 병합 정렬(Merge Sort)에 대해 포스팅하겠습니다. 병합 정렬은 정렬되지 않은 전체 데이터를 하나의 단위로 분할한 후에 분할한 데이터들을 다시 병합하며 정렬하는 방식 입니다. 즉, Divide: n개의 데이터를 n/2개 데이터로 나누고 2개의 리스트에 넣습니다.Conquer: 2개의 리스트들의 데이터가 하나가 될 때까지 재귀적으로 나눕니다.Combine: 각각의 2개의 리스트를 병합 합니다. 시간 복잡도는 최악의 경우 O(nlogn)로 이전 포스팅에서 소개했던 insertion sort보다 효율적인 알고리즘 입니다. 코드를 통해 자세히 보겠습니다. 우선, 데이터를 리스트로 입력 받겠습니다.입력 받은 데이터를 띄어쓰기 기준으로 구분하여 이를 정수형으로 리스트에 저장.. 2018. 3. 30. [Python] Insertion Sort: 삽입정렬 안녕하세요. 우주신 입니다. 오늘은 삽입 정렬(Insertion Sort)에 대해 포스팅하겠습니다. 알고리즘을 배울 때, 가장 먼저 접하게 되는 친숙한 삽입 정렬입니다.삽입 정렬은 말 그대로 데이터의 삽입을 통해 정렬을 완성하는 알고리즘 입니다.현재 위치에서, 이미 정렬된 이전 배열들의 데이터를 차례대로 비교하여 자신의 위치를 찾아 그 위치에 삽입하는 방식 입니다. 시간 복잡도는 최악의 경우 O(n^2)이고, 최선의 경우(이미 정렬되어 있는 경우)에는 O(n) 이므로 Big-O (n^2) 입니다. 5 3 4 6 1 2 5 3 4 6 1 2 3 5 4 6 1 2 3 4 5 6 1 2 3 4 5 6 1 2 1 3 4 5 6 2 1 2 3 4 5 6 파이썬 코드를 통해 자세히 알아보겠습니다. 우선, 데이터를 .. 2018. 3. 29. 이전 1 다음