 [R] 상관분석(Correlation Analysis), [산점도, 공분산, 상관계수, 상관계수의 검정]
안녕하세요. 우주신입니다. 이번 포스팅과 다음 포스팅에서는 매우 중요한 상관분석(correlation analysis)과 회귀분석(regression analysis)에 대해 정리해보겠습니다. plot(), corrplot(), cov(), cor(), cor.test() 우리는 종종 어떤 두 사건 간의 연관성을 분석해야 할 경우가 많습니다. 둘 또는 그 이상의 변수들이 서로 관련성을 가지고 변화할 때 그 관계를 분석하는데 사용되는 방법 중에서 가장 잘 알려진 것이 상관분석(correlation analysis)과 회귀분석(regression analysis)입니다. GDP와 기대수명 간의 관계, 키와 몸무게 간의 관계 등을 예로 들 수 있는데 여기에서 두 사건, 즉 두 변수 간의 선형적 관계를 상관(c..
2017. 3. 1.
[R] 상관분석(Correlation Analysis), [산점도, 공분산, 상관계수, 상관계수의 검정]
안녕하세요. 우주신입니다. 이번 포스팅과 다음 포스팅에서는 매우 중요한 상관분석(correlation analysis)과 회귀분석(regression analysis)에 대해 정리해보겠습니다. plot(), corrplot(), cov(), cor(), cor.test() 우리는 종종 어떤 두 사건 간의 연관성을 분석해야 할 경우가 많습니다. 둘 또는 그 이상의 변수들이 서로 관련성을 가지고 변화할 때 그 관계를 분석하는데 사용되는 방법 중에서 가장 잘 알려진 것이 상관분석(correlation analysis)과 회귀분석(regression analysis)입니다. GDP와 기대수명 간의 관계, 키와 몸무게 간의 관계 등을 예로 들 수 있는데 여기에서 두 사건, 즉 두 변수 간의 선형적 관계를 상관(c..
2017. 3. 1.
 [R] 비교연산자, 논리연산자
안녕하세요. 우주신입니다. 오늘은 비교연산자와 논리 연산자에 대해 배워보겠습니다. >, =, 3만 TRUE가 나온 것을 알 수 있습니다. 같은 원리로, X가 Y보다 값이 작다면 TRUE가 아니라면 FALSE가 결과값으로 출력됩니다. Z는 구성요소가 하나임에도 X와 비교연산이 되는 것을 볼 수 있습니다. 이러한 경우에는, Z가 X의 길이에 자동으로 맞추어(4, 4, 4, 4, 4, 4) 비교연산이 이루어 집니다. 부등호 '>='는 '왼쪽항이 오른쪽 항보다 크거나 같다'는 뜻입니다. 반대로, 부등호 '
2017. 2. 25.
[R] 비교연산자, 논리연산자
안녕하세요. 우주신입니다. 오늘은 비교연산자와 논리 연산자에 대해 배워보겠습니다. >, =, 3만 TRUE가 나온 것을 알 수 있습니다. 같은 원리로, X가 Y보다 값이 작다면 TRUE가 아니라면 FALSE가 결과값으로 출력됩니다. Z는 구성요소가 하나임에도 X와 비교연산이 되는 것을 볼 수 있습니다. 이러한 경우에는, Z가 X의 길이에 자동으로 맞추어(4, 4, 4, 4, 4, 4) 비교연산이 이루어 집니다. 부등호 '>='는 '왼쪽항이 오른쪽 항보다 크거나 같다'는 뜻입니다. 반대로, 부등호 '
2017. 2. 25.
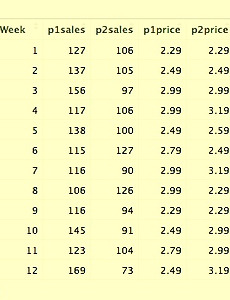 [R] 기술통계(Descriptive Statistics) 함수
안녕하세요. 우주신입니다. 이번 포스팅과 다음 포스팅 두번 나누어 기술통계(Descriptive Statistics) 함수에 대해 다뤄보겠습니다. 기술통계는 관측한 데이터를 도표로 정리하거나 통계량(예: 평균, 분산, 상관계수, 주성분정준변량)으로 정리하는 것으로서 관측한 현상의 특징을 기술한다.[출처: 네이버 지식백과] 먼저, 데이터를 확인하는 함수들 부터 살펴보고head( ), tail( ), some( ), str( )데이터를 요약하는 방법을 보겠습니다.min( ), max( ), mean( ), median( ), var( ), sd( ), range( ), quantile( ), summary( ), apply( ) 그 외 attach( ), detach( ) 함수에 대해 배워보겠습니다. 1. ..
2017. 2. 11.
[R] 기술통계(Descriptive Statistics) 함수
안녕하세요. 우주신입니다. 이번 포스팅과 다음 포스팅 두번 나누어 기술통계(Descriptive Statistics) 함수에 대해 다뤄보겠습니다. 기술통계는 관측한 데이터를 도표로 정리하거나 통계량(예: 평균, 분산, 상관계수, 주성분정준변량)으로 정리하는 것으로서 관측한 현상의 특징을 기술한다.[출처: 네이버 지식백과] 먼저, 데이터를 확인하는 함수들 부터 살펴보고head( ), tail( ), some( ), str( )데이터를 요약하는 방법을 보겠습니다.min( ), max( ), mean( ), median( ), var( ), sd( ), range( ), quantile( ), summary( ), apply( ) 그 외 attach( ), detach( ) 함수에 대해 배워보겠습니다. 1. ..
2017. 2. 11.
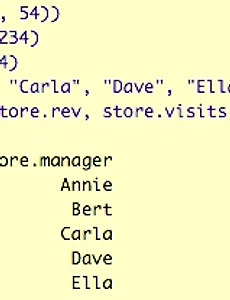 [R] 데이터프레임(DataFrame) 변수명 변경, 변수 선택 및 정렬
안녕하세요. 우주신입니다. 이전 포스팅에 이어 오늘은 데이터프레임 변수명 변경, 변수 선택 및 정렬에 대해 정리해보겠습니다. 우선, 매장 번호, 수입, 방문자수, 매니저로 구성된 데이터프레임을 하나 만들어보겠습니다. 1. 데이터프레임 변수명 변경 변수명 변경에는 두 가지 방법이 있습니다. 첫번째는 names( ) 함수를 사용해서 변경.names(dataframe) 이 두 명령어만 입력하면 패키지 안의 함수들을 사용할 수 있습니다. V1, V2, V3, V4 변수명이 다시 바뀐 것을 확인할 수 있죠? 2. 데이터프레임 변수 선택 데이터프레임을 사용하다보면 특정 변수를 선별해야 하는 경우가 많습니다.먼저, index[which( )] 함수에 대해 알아보겠습니다.dataframe[which(조건, 변수선택)]..
2017. 2. 7.
[R] 데이터프레임(DataFrame) 변수명 변경, 변수 선택 및 정렬
안녕하세요. 우주신입니다. 이전 포스팅에 이어 오늘은 데이터프레임 변수명 변경, 변수 선택 및 정렬에 대해 정리해보겠습니다. 우선, 매장 번호, 수입, 방문자수, 매니저로 구성된 데이터프레임을 하나 만들어보겠습니다. 1. 데이터프레임 변수명 변경 변수명 변경에는 두 가지 방법이 있습니다. 첫번째는 names( ) 함수를 사용해서 변경.names(dataframe) 이 두 명령어만 입력하면 패키지 안의 함수들을 사용할 수 있습니다. V1, V2, V3, V4 변수명이 다시 바뀐 것을 확인할 수 있죠? 2. 데이터프레임 변수 선택 데이터프레임을 사용하다보면 특정 변수를 선별해야 하는 경우가 많습니다.먼저, index[which( )] 함수에 대해 알아보겠습니다.dataframe[which(조건, 변수선택)]..
2017. 2. 7.
 [R] 벡터(Vector) 기본함수 및 인덱싱
안녕하세요! 우주신입니다. 오늘은 데이터 구조 중 하나인 벡터(Vector)에 대해 배워보겠습니다. 앞시간에 설명했듯이, 벡터는 동일한 유형의 데이터로 구성되어 있는 1차원 데이터 구조입니다. 가장 기본적인 데이터 구조로서 정말 많이 쓰이죠. 벡터와 관련해 많은 기능과 함수가 존재하지만 가장 기초적인 것부터 살펴 보겠습니다. [ 사칙 연산 ] R에서 사용하는 연산자는 +(덧셈), -(뺄셈), *(곱셈), /(나눗셈), %/%(정수나눗셈), %%(나머지), ^(제곱) 등이 있습니다.우선순위는 괄호, 지수 및 근호, 곱하기와 나누기, 더하기와 빼기 순서인 표준적인 연산의 우선순위와 같습니다. 연산을 하기 위해 길이가 4인 벡터 X와 Y를 만든 후, +(덧셈)과 *(곱셈)을 해봤습니다.나머지 연산자들도 직접 ..
2017. 1. 27.
[R] 벡터(Vector) 기본함수 및 인덱싱
안녕하세요! 우주신입니다. 오늘은 데이터 구조 중 하나인 벡터(Vector)에 대해 배워보겠습니다. 앞시간에 설명했듯이, 벡터는 동일한 유형의 데이터로 구성되어 있는 1차원 데이터 구조입니다. 가장 기본적인 데이터 구조로서 정말 많이 쓰이죠. 벡터와 관련해 많은 기능과 함수가 존재하지만 가장 기초적인 것부터 살펴 보겠습니다. [ 사칙 연산 ] R에서 사용하는 연산자는 +(덧셈), -(뺄셈), *(곱셈), /(나눗셈), %/%(정수나눗셈), %%(나머지), ^(제곱) 등이 있습니다.우선순위는 괄호, 지수 및 근호, 곱하기와 나누기, 더하기와 빼기 순서인 표준적인 연산의 우선순위와 같습니다. 연산을 하기 위해 길이가 4인 벡터 X와 Y를 만든 후, +(덧셈)과 *(곱셈)을 해봤습니다.나머지 연산자들도 직접 ..
2017. 1. 27.
 [R] 데이터 구조 (벡터, 요인, 행렬, 배열, 데이터프레임, 리스트)
안녕하세요! 우주신입니다. 오늘은 R 데이터 구조에 대해 배워보겠습니다. 정말 중요한 부분입니다. 지금 잘 짚고 넘어가지 않는다면, 나중에 머리털 다 빠집니다. 이론적으로 한번 보시고, 꼭 직접 해보시길 부탁드립니다. R 데이터 구조는 1. 벡터 2. 요인 3. 행렬 4. 배열 5. 데이터프레임 6. 리스트로 나뉩니다. 찬찬히 하나씩 보겠습니다. 1. 백터 (Vector) 앞 시간에서 잠시 언급했지만 벡터는 동일한 유형의 데이터로 구성되어 있는 1차원 데이터 구조입니다.숫자형은 숫자형끼리, 문자형은 문자형끼리, 논리형은 논리형끼리. 2. 요인 (Factor) 요인형은 범주형의 데이터 입니다.( 1, 2, 3은 숫자이지만, 첫번째, 두번째, 세번째는 범주형이다 ) 범주형으로 만들기 위해선 먼저, 범주 카테..
2017. 1. 25.
[R] 데이터 구조 (벡터, 요인, 행렬, 배열, 데이터프레임, 리스트)
안녕하세요! 우주신입니다. 오늘은 R 데이터 구조에 대해 배워보겠습니다. 정말 중요한 부분입니다. 지금 잘 짚고 넘어가지 않는다면, 나중에 머리털 다 빠집니다. 이론적으로 한번 보시고, 꼭 직접 해보시길 부탁드립니다. R 데이터 구조는 1. 벡터 2. 요인 3. 행렬 4. 배열 5. 데이터프레임 6. 리스트로 나뉩니다. 찬찬히 하나씩 보겠습니다. 1. 백터 (Vector) 앞 시간에서 잠시 언급했지만 벡터는 동일한 유형의 데이터로 구성되어 있는 1차원 데이터 구조입니다.숫자형은 숫자형끼리, 문자형은 문자형끼리, 논리형은 논리형끼리. 2. 요인 (Factor) 요인형은 범주형의 데이터 입니다.( 1, 2, 3은 숫자이지만, 첫번째, 두번째, 세번째는 범주형이다 ) 범주형으로 만들기 위해선 먼저, 범주 카테..
2017. 1. 25.











