안녕하세요~ 우주신 입니다.
저번 상관분석 포스팅에 이어 이번에는 회귀분석(Regression Analysis)에 대해 정리 해보겠습니다.
상관분석은 변수들이 서로 얼마나 밀접하게 직선적인 관계를 가지고 있는지를 분석하는 통계적 기법이며,
(바로 이전 글에 자세히 다뤄봤으니 참고)
회귀분석은 한 개 또는 그 이상의 변수들(독립변수)에 대하여 다른 변수(종속변수) 사이의 관계를
수학적인 모형을 이용하여 설명하고 예측하는 분석기법 입니다.
쉽게 말하자면, 상관분석에서는 산점도의 점들의 분포를 통해 일정한 패턴을 확인한 후,
상관계수를 구하여 두 변수 간의 선형 관계를 알 수 있었습니다.
여기서 더 나아가, 이 일정한 패턴을 활용하여 무엇인가를 예측하는 분석을 회귀분석이라고 보시면 됩니다.
회귀분석 하면 괜히 이름도 생소하고 낯설 수 있지만, 코드와 함께 따라가보시죠.
상관분석의 연장선에서 설명하고자 회귀분석에서도 같은 데이터를 사용하겠습니다.
이번 예시에서는 당뇨와 그에 영향을 미치는 변수들 간의 관계를 분석해 보죠.
먼저 데이터는 sklearn에서 제공하는 datasets을 불러왔습니다.
import pandas as pd
import numpy as np
from sklearn import datasets
data = datsets.load_diabetes()데이터가 dictionary 형태이므로 어떤 key를 가지는지 확인해보면 아래와 같이 나오고,

여기서 data, target, feature_names 세 가지 key만 쓰겠습니다. 당연히 데이터 형태의 길이가 같은지 부터 확인해야죠.
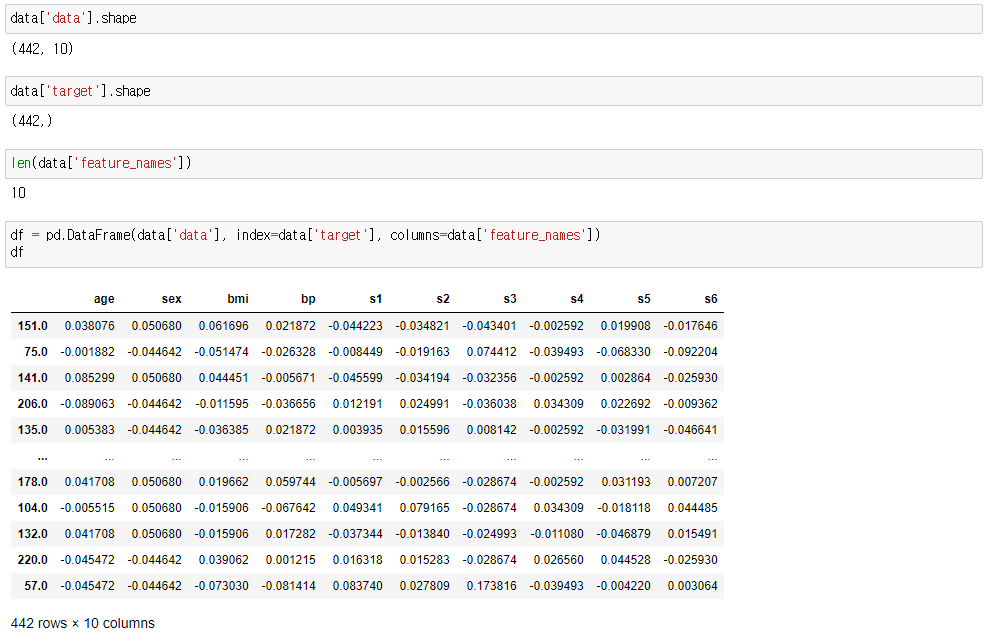
여기서 target이 당뇨병의 수치이고 나머지 feature names에 속하는 age, sex, bmi 등등은 변수라고 보면 됩니다.
즉, 442명의 사람들을 상대로 10가지의 특성들을 나열한거죠.
저번 포스팅의 상관분석을 통해 당뇨병의 수치(target)와 bmi(체질량지수) 간의 일정한 패턴을 확인하였고, 상관계수 또한 0.59로써 양의 선형관계를 이뤘습니다. 여기서 더 나아가, 회귀분석을 통해 변수 간에 관계를 예측해보죠.
회귀분석은 크게 독립변수 종속변수가 각각 한 개일 때의 관계를 분석하는 단순선형회귀분석(simple linear regression analysis)과 종속변수는 한개 독립변수는 두개 이상일 때는 중선형회귀분석(multiple linear regression analysis)으로 구분 됩니다.
<단순선형회귀분석>
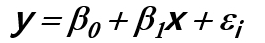
1. 회귀식의 추정
두 변수 X와 Y의 관계(bmi, target)에 적합한 회귀식을 구하기 위해서는 관측된 값으로부터 회귀계수 B0와 B1의 값을 추정하여야 합니다.
이 때 일반적으로 많이 사용되는 방법을 최소제곱법이라고 합니다.
여러가지 방법으로 회귀분석을 해 볼 수 있는데, 오늘은 sklearn 패키지를 사용해보겠습니다.
먼저, sklearn에서 제공하는 linear_model을 import 하죠.
from sklearn.linear_model import LinearRegression
lr = LinearRegression()위와 같이 lr 변수를 생성했다면, 이제 우리는 lr 하나로 간단하게 회귀분석을 할 수 있습니다.
먼저, Y, X의 데이터를 정해야겟죠.
아까 위에서 정의한 데이터프레임 df에서 Y는 index가 될 것이고, X는 bmi로 정할 수 있습니다.


여기서 주의해야할 점이, X와 Y 모양 자체를 2d array를 바꿔줘야 합니다.
X = X.reshape(-1,1)
Y = Y.reshape(-1,1)이는 위와 같은 방법으로 쉽게 변환이 가능하며, 아래와 같은 모양으로 바뀌게 됩니다.

자, 모든 준비가 끝났습니다. 이제 회귀분석을 돌리면 됩니다.
lr.fit(X, Y)X를 먼저 넣고 Y를 차례대로 변수로 입력해주고 실행하면 끝.
이제 회귀분석 결과를 보면, 아래와 같이 회귀 계수를 구할 수 있고, 여기서는 B1=949.435, B0=152.133으로 결과 값이 나왔네요.

앞선 시간에 배운 scatter plot에 회귀식을 그려보죠.
import matplotlib.pyplot as plt
plt.scatter(X, Y)
plt.plot(X, Y2, color='red')
plt.title('y = {}*x + {}'.format(lr.coef_[0], lr.intercept_))
plt.show()
두 변수의 관계를 회귀식으로 표현하면 Target = 949 * BMI + 152이고,
이는 Target의 수치가 1 증가할 때마다 BMI가 949만큼 증가한다고 볼 수 있습니다.
2. 회귀모형의 검정 및 적합도 파악
이 회귀식이 통계적으로 유의한지, 변수가 유의하게 영향을 미치는 지, 그리고 얼만큼의 설명력을 가지는지 등의 여부를 확인해야 합니다.
A. F-statistic
도출된 회귀식이 회귀분석 모델 전체에 대해 통계적으로 의미가 있는지 파악
B. P-Value
각 변수가 종속변수에 미치는 영향이 유의한지 파악
C. 수정된 R제곱
회귀직선에 의하여 설명되는 변동이 총변동 중에서 차지하고 있는 상대적인 비율이 얼마인지 나타냄
즉, 회귀직선이 종속변수의 몇%를 설명할 수 있는지 확인
이번에는 다른 패키지를 통해 위에 나온 3가지 모두 확인해보겠습니다.
마법의 statsmodels 패키지를 아래와 같이 import 하고 회귀분석을 돌려보죠.
import statsmodels.api as sm
results = sm.OLS(Y, sm.add_constant(X)).fit()
그리고 회귀분석의 결과를 results로 받은 후, 아래와 같이 summary()를 입력해주면 자세한 회귀분석 결과가 도출 됩니다.
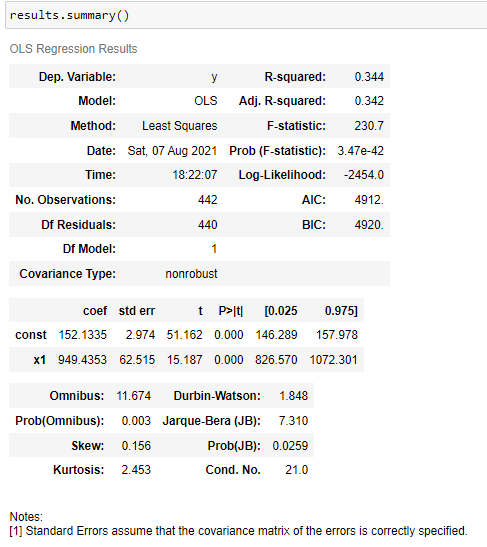
결과를 보면 잔차에 대한 정보, 회귀계수에 대한 정보, R제곱, 검정통계량 F0 값과 P-value 값 등 자세하게 출력된 것을 확인할 수 있습니다.
A. F-statistic의 p-value 값은 Prob(F-statistic)으로 표현되는데, 이는 3.47e-42로 0.05보다 작기에 이 회귀식은 회귀분석 모델 전체에 대해 통계적으로 의미가 있다고 볼 수 있습니다.
B. 중간쯤에 보면 coef와 변수 x1의 p-value 값이 나와있습니다. 여기서 x1은 bmi이고 이 변수의 p-value가 0.000으로 표기 되어 있기에 0.05보다 작으므로 target을 설명하는데 유의하다고 판단할 수 있습니다.
C. 제일 위 부분에 R-squared와 Adj. R-squared가 표기되어 있는데, 값이 0.34정도로 이는 34%만큼의 설명력을 가진다고 판단할 수 있습니다. 참고로, 0에 가까울 수록 예측값을 믿을 수 없고 1에 가까울 수록 믿을 수 있다고 보면 됩니다.
이번에는 똑같은 원리로 중선형회귀분석을 해보죠.
<중선형회귀분석>
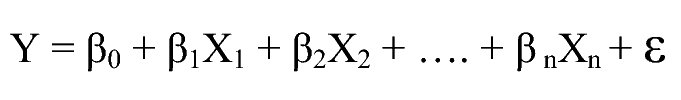
위 단순선형회귀분석과 비교했을 때 종속변수를 설명하는 독립변수가 두개 이상으로 증가했다고 생각하시면 됩니다.

기존에는 bmi만 독립변수로 가지고 있었다면, age와 sex를 추가해보죠.
그리고 위와 똑같은 순서로 회귀식을 돌려 결과 값을 보고 해석해 봅시다.
import statsmodels.api as sm
results = sm.OLS(Y, sm.add_constant(X)).fit()
results.summary()
회귀식은 Target = 926*bmi + 138*age - 36*sex + 152 로 도출이 될 수 있습니다.
A. F-statistic의 p-value 값은 Prob(F-statistic)으로 표현되는데, 이는 7.77e-41로 0.05보다 작기에 이 회귀식은 회귀분석 모델 전체에 대해 통계적으로 의미가 있다고 볼 수 있습니다.
B. 중간쯤에 보면 coef와 여러 변수들의 p-value 값이 나와있습니다. 여기서 x1과 x2는 변수의 p-value가 0.05 미만으로 유의미 하다고 볼 수 있지만 x3의 p-value는 0.569로 0.05보다 크기에 유의미하다고 판단할 수 없습니다. 즉, sex는 target을 설명하는데 유의하다고 판단할 수 없습니다.
C. 제일 위 부분에 R-squared와 Adj. R-squared가 표기되어 있는데, 값이 0.35정도로 이는 35%만큼의 설명력을 가진다고 판단할 수 있습니다.
앞선 결과와 비교 했을 때, 사실상 설명력이 더 높아지진 않았네요.
끝~
'Python > Basic Data Analysis' 카테고리의 다른 글
| [Python] 람다 관련 (apply, applymap) (0) | 2022.04.26 |
|---|---|
| [Python] 람다 관련 (lambda, map) (0) | 2022.04.26 |
| [Python] 상관분석(Correlation Analysis), [산점도, 공분산, 상관계수, 검정] (4) | 2021.03.05 |
| [Python] matplotlib 이용하여 누적영역형차트, 원형차트 그리기 (0) | 2018.01.02 |
| [Python] matplotlib 이용하여 히스토그램, 산점도 그리기 (0) | 2017.12.29 |




댓글